Local Port Weiterleitung mit SSH
Sichere Verbindung zu entfernten Diensten
Das Programm SSH lässt sich nicht nur als sichere Alternative zu telnet einsetzen, sondern bietet auch die Möglichkeit, eine sichere Verbindung zu anderen sonst unerreichbaren Diensten herzustellen.
Wenn es darum geht, auf sichere Art und Weise eine Konsole auf einem entfernten, nur über das Internet erreichbaren Rechners zu verwenden, hat sich das Programm SSH gegenüber den früher benutzten Programmen wie telnet oder rlogin durchgesetzt. Ein SSH-Server läuft auf nahezu jedem Rechner bzw. kann auf jedem Rechner laufen und SSH-Clients gibt es für jedes Betriebssystem, inklusive mobile.
Weniger bekannt sind die weiteren Möglichkeiten, die SSH bietet, und dazu gehört vor allem die Port Weiterleitung, die als Local Port Weiterleitung und als Remote Port Weiterleitung (manchmal auch Reverse Port Weiterleitung genannt) eingesetzt werden kann.
In diesem Artikel soll es zunächst um ein einfaches Beispiel für die Local Port Weiterleitung gehen. Dazu ist es interessant, ganz grob zu wissen, wie die Kommunikation von Anwendungen im Internet funktioniert.
Anwendungskommunikation im Internet
Ein bekanntes Szenario ist beipielsweise eine Web-Anwendung auf einem Rechner im Internet. Die Anwendung wird durch einen Web-Server zur Verfügung gestellt und verwendet zur Datenhaltung eine Datenbank, deren Datenbank-Server üblicherweise auf dem gleichen Rechner installiert ist.
Da zum Funktionieren der Anwendung eigentlich nur der Web-Server mit dem Datenbank-Server kommunizieren muss, genügt es, wenn der Datenbank-Server auch nur vom gleichen, "lokalen" Rechner aus erreichbar ist. Damit ist der Datenbank-Server gegen unbefugte Anfragen von außerhalb geschützt, denn er reagiert erst gar nicht darauf. Der Web-Server muss dagegen auch von außerhalb des Rechners erreichbar sein, sonst könnte ja niemand die Anwendung im Browser aufrufen und verwenden.
Technisch wird das so umgesetzt, dass der Web-Server sowohl auf der nach innen als auch auf der nach außen gerichteten Netzwerkschnittstelle kommunizieren kann, während der Datenbank-Server nur auf der nach innen gerichteten Schnittstelle erreichbar ist.
Die nach außen gerichtete Schnittstelle ist hier z.B. mit dem Namen remote.example.com bzw. der zugehörigen IP-Adresse 140.230.120.210 erreichbar, die nach innen gerichtete Schnittstelle mit dem Namen localhost bzw. der zugehörigen IP-Adresse 127.0.0.1.
In einer Konsole auf dem entfernten Rechner lässt sich mit dem Programm netstat zeigen, welche Anwendung (PID/Program name) auf welcher Schnittstelle (Local Address) erreichbar ist. Die Adresse 0.0.0.0 steht dabei für "alle Schnittstellen":
$ sudo netstat -ltpn
Aktive Internetverbindungen (Nur Server)
Proto Local Address Foreign Address State PID/Program name
tcp 0.0.0.0:22 0.0.0.0:* LISTEN 531/sshd
tcp 127.0.0.1:3306 0.0.0.0:* LISTEN 624/mysqld
tcp 0.0.0.0:80 0.0.0.0:* LISTEN 745/apache2
$Der vereinfachten und verkürzten Ausgabe ist zu entnehmen, dass der Datenbank-Server (MySQL) nur über die lokale Schnittstelle erreichbar ist (127.0.0.1), während zum Beispiel der SSH-Server und der Web-Server (Apache) über alle Schnittstellen, also auch vom Internet aus erreichbar sind (0.0.0.0).
Die Zahl nach der Adresse ist dabei der von dieser Anwendung verwendete Port, was etwa mit einem Kanal beim Funken vergleichbar ist. Jede Anwendung, die über das Internet kommunizieren will, verwendet dafür einen oder mehrere Ports. Den Anwendungen sind dabei bestimmte Portnummern per Konvention zugewiesen, die Anwendungen können aber auch andere Portnummern verwenden, was allerdings bei der Kommunikation zu berücksichtigen ist.
Der Web-Server wäre hier mit der URL http://remote.example.com/ erreichbar, aber auch http://remote.example.com:80/ wäre korrekt, denn der Web-Server verwendet seinen Standardport 80 und in diesem Fall kann man auf die Angabe des Ports in der Adresse verzichten.
Der Ausgabe von netstat ist also auch zu entnehmen, dass der Web-Server auf Port 80 (über alle Schnittstellen) erreichbar ist, der SSH-Server auf Port 22 (ebenfalls über alle Schnittstellen) und der Datenbank-Server auf Port 3306 (nur über die lokale Schnittstelle). Das sind auch die Standardports der betreffeneden Anwendungen.
Die Frage ist nun, wie man trotzdem, zum Beispiel vom heimischen Laptop aus, eine Verbindung zum Datenbank-Server herstellen kann, um mit einem Programm auf dem Laptop die Datenbank verwalten zu können. Das Programm erwartet dabei, dass der zu verwaltende Datenbank-Server mit dem Namen des Rechners und dem Port konfiguriert wird, also z.B. remote.example.com:3306.
Genau das ist aber nicht möglich, da der Datenbank-Server nicht über die nach außen gerichtete Schnittstelle erreichbar ist. Nur der Web-Server und der SSH-Server sind aus der Ferne erreichbar. Für den Datenbank-Server muss es daher so aussehen, als wenn unsere Verbindungsanfrage von der nach innen gerichteten Schnittstelle auf dem Server kommt.
Hier kommt die Local Port Weiterleitung ins Spiel. Mit ihr lässt sich ein beliebiger freier, lokaler Port zu einem entfernten (und dort wiederum lokalen) Port weiterleiten.
Local Port Weiterleitung starten
Die Weiterleitung wird durch einen sogenannten "Tunnel" mit Hilfe einer SSH-Verbindung auf Port 22 vom lokalen Rechner (Laptop) zum entfernten Rechner (Server) eingerichtet:
$ ssh -f -N -L 3306:127.0.0.1:3306 remote.example.comMit dem Parameter -f wird ssh in den Hintergrund versetzt und -N gibt an, dass kein Befehl auf dem entfernten Rechner auszuführen ist.
Der wichtigste Parameter ist hier jedoch -L, mit dem die Local Port Weiterleitung eingerichtet wird. Der Wert für den Parameter -L ist ganz allgemein:
[LOCALHOST:]LOCALPORT:REMOTEHOST:REMOTEPORT
Zuerst muss also der lokale Hostname oder die lokale IP (LOCALHOST) und der zu verwendende Port (LOCALPORT) angegeben werden, dann der entfernte Hostname oder die entfernte IP (REMOTEHOST) und der dortige zu verwendende Port (REMOTEPORT). Die Angabe des LOCALHOST ist optional. Wichtig ist jedoch, dass als REMOTEHOST die Adresse angebenen wird, auf der der Service auch erreichbar ist, das ist in unserem Falle die Adresse 127.0.0.1.
Es wird also eine Port Weiterleitung vom lokalen Port 3306 zum entfernten Port 3306 eingerichtet. Sollte der lokale Port 3306 belegt sein, weil es auch einen Datenbank-Server auf dem lokalen Rechner gibt, wäre irgendein anderer freier lokaler Port zu wählen.
Anstelle des Namens remote.example.com könnte man am Ende des ssh Befehls auch die IP des Servers verwenden. Und sollte der Benutzername mit dem dieser Befehl auf dem lokalen Rechner ausgeführt wird, nicht identisch sein mit dem Benutzernamen auf dem Server, wäre USER@remote.example.com anstatt nur remote.example.com zu verwenden, wobei USER dann der Benutzername auf dem entfernten Rechner ist.
Die nachfolgende Abbildung verdeutlicht das Prinzip:
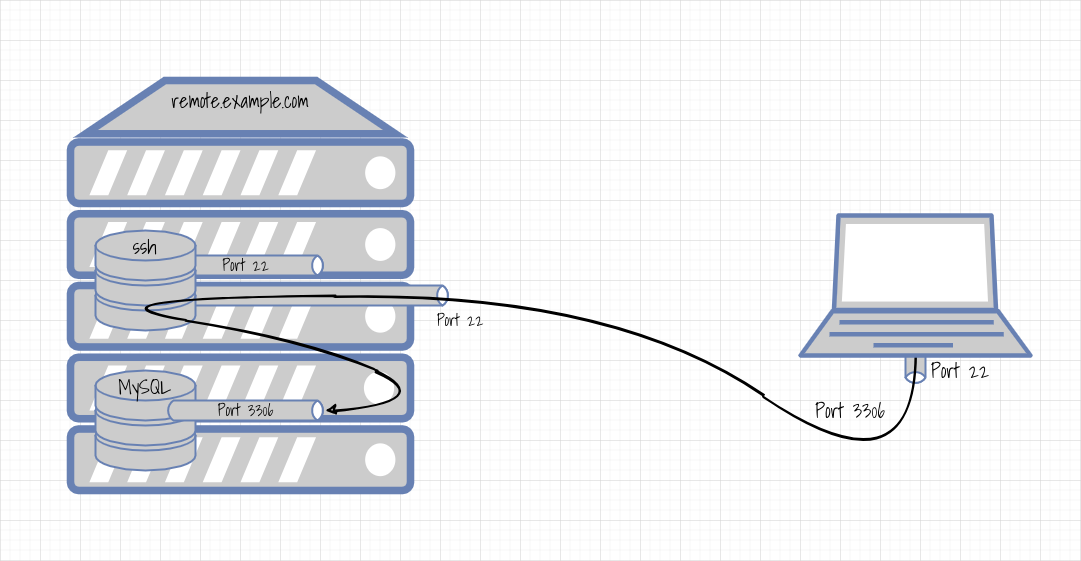
Von einem Laptop aus möchte man die Datenbank auf dem Server remote.example.com administrieren. Der MySQL-Server ist auf Port 3306, jedoch nur von "innerhalb" des entfernten Rechners erreichbar. Dagegen ist der SSH-Server auf Port 22 von innerhalb und außerhalb erreichbar. Vom Laptop aus wird eine Port Weiterleitung eingerichtet, die den Port 3306 vom Laptop über SSH auf den Server "tunnelt" und am dortigen lokalen Port 3306 endet.
Der zu verwaltende Datenbank-Server würde also in dem lokalen Programm nicht mit remote.example.com:3306 konfiguriert, sondern mit localhost:3306.
Local Port Weiterleitung beenden
Zum Beenden der Port Weiterleitung ermittelt man auf dem lokalen Rechner deren Prozess ID und sendet ein SIGTERM Signal an diesen Prozess, z.B. wie folgt:
$ ps -C ssh -o pid=,cmd=
28364 /usr/bin/ssh -f -N -L 3306:127.0.0.1:3306 remote.example.com
$ kill 28364